Anti-fragile Software
Before proceeding further, I have a confession to make - it has mostly nothing to do with ABAP development and it even spans other areas of SAP. For simulation of fault tolerance systems, I used non SAP software However, as it concerns software development and in SAP space what better subspace than ABAP to get opinions of developers, I'm putting it in ABAP development. Hopefully it will be of some use.
I recently read “Anti-Fragile” from Nicolas Nassim Taleb and it kept me wrapped till my eyes were hurting. It is a very good read even though I may not agree with all his notions. Taleb coined the term ‘antfragile’ as there was no English word for what he wanted to express, though there’s a mathematical term - long complexity.
Taleb categorizes objects in the following triads:
- Fragile : This is something that doesn’t like volatility. An example will be a package of wine glasses you’re sending to a friend.
- Robust : This is the normal condition of most of the products we expect to work. It will include the wine glasses you’re sending to the friend, our bodies ,computer systems.
- Antifragile: These gain from volatility. It’s performance thrives when confronted with volatility.
Here volatility means an event that induces stress.If fragile loses from volatility and robustness merely tolerates adverse conditions, the object that gains from volatility is antifragile. Our own bodies are healthier over time with non linear exposure to temperature and food. Our immune systems become better when attacked by disease. And as it’s now obvious in Australia, small naturally occurring fires prevent bigger fires. Spider webs are able to resist winds of hurricanes - a single thread breaks allowing the rest of the web to remain unharmed.
Taleb’s book mostly considers the notions of fragility and antifragility in biological, medical, economic, and political systems. He doesn’t talk about how this can apply to software systems but there are some valuable lessons we can draw when it comes to software systems. Failures can result from a variety of causes - mistakes are made and software bugs can be in hibernation for a long time before showing up. As these failures are not predictable, the risk and uncertainty in any system increases with time.In some ways, the problem is similar to a turkey fed by the butcher - for a thousand days, the turkey is fed by the butcher and each day the turkey feels that statistically, the butcher will never hurt him. In fact the confidence is highest just before Thanksgiving.
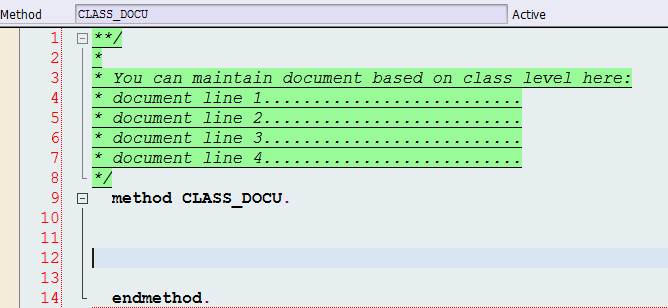
Traditionally we have been designing software systems trying to make them robust and we expect them to work under all conditions.This is becoming more challenging as software is becoming much more complex and the number of components is increasing. We use technology stacks at higher levels of abstractions. Further, with onset of cloud, there might be parts which are not even in your own direct control. Your office might be safe but what happens if data centers where the data and applications reside get hit by the proverbial truck.
We try to prove the correctness of a system through rigorous analysis using models and lots of testing. However, both are never sufficient and as a result some bugs always show up in production – especially while interacting with other systems.
For designing many systems, we often look at nature – nature is efficient and wouldn’t waste any resources. At the same time, it has anti-fragility built in – when we exercise, we’re temporarily putting stress on body. Consequently, body overshoots in it’s prediction for next stressful condition and we become stronger.If you lift 100 kg, your body prepares itself for lifting 102 kg next time.
We spend a great deal of effort in making a system robust but much in making it antifragile.The rough equivalent of antifragile is resilience in common language - it is an attribute of a system that enables it to deal with failure in a way that doesn’t cause the entire system to fail. There are two ways to increase resilience in systems.
a) Create fault tolerant applications:The following classical best practices aid in this goal.
- Focus is better than features: Keep classes small and focused - they should be created for a specific task and should do it well. If you see new extraneous features being added, it’s better to create separate classes for them.
- Simplicity is better than anything: Keeping the design simple - It may be fun to use dynamic programming using ABAP RTTI / Java Reflection but if it’s not required, don’t do it.
- Keep high cohesion and loose coupling: If the application is tightly coupled, making a change is highly risky.It makes the code harder to understand as it becomes confusing when it’s trying to do two things at the same time ( e.g. try to do data access and execute a business logic at the same time ). Any change to the business logic change will have to rip through data access parts. As an example, whenever the system needs to communicate with an external system ( say you’re sending messages via an ABAP proxy to PI / some external systems ) , keep the sending part as a V2 update. You don’t want to block the main business transaction processing or hang on to locks.If there are issues with the receiving system being slow or non available, it’ll ensure that your main business document processing doesn’t get affected.
And keeping fault tolerance in mind, the following ideas can help.
- While putting any new code in production, make it unpluggable in case things go wrong.
- Create tools to deal with scenarios when things go wrong. Taking the example scenario when we’re not able to send messages as the external system is down / unable to keep up with the throughput, we should have transactions that can resend these messages after identifying them.
Replica Sets and Sharding: As developers we may not have to worry about too much building fault tolerant infrastructure but it’s helpful to know the following concepts.
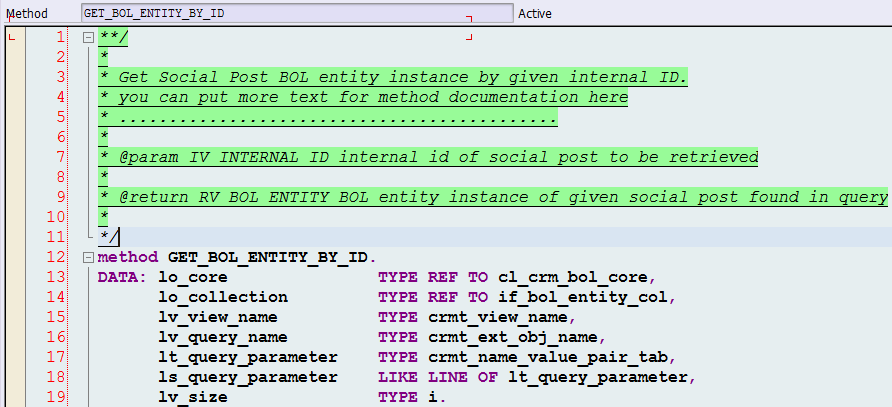
- Replica Sets: Create a set of replication nodes for redundancy . If the primary node fails the secondary nodes get activated as primary. For instance, in a three node scenario we can have a primary where all the writes happen ( in green ) and the secondaries ( in red )are asynchronously updated. In case the primary fails, one of the secondaries can become the primary. There can be further variations where reads can be delegated to secondaries if freshness of data is not a concern ( e.g. writes to some data set happens very rarely or at times when the likelihood of application requiring data is very small ).

For simulation, I created a replication set and made the primary node fail. This is how things look when things are going on smoothly . dB writes are issued and the callbacks confirm that the write is successful.

Now, I made the primary node fail so that the secondary becomes the primary. We’re issuing inserts but as the secondary takes some time to become primary, the writes are cached in the dB driver before it gets completed and the callbacks confirm of the update.

Sharding: It’s a horizontal partition of data - i.e. divide the data set into multiple servers or shards.
Vertical scaling on contrast aims to add more resources to a single node which is disproportionately more expensive than using smaller systems.

And sharding and replica sets can be combined .

Integration: Here again, some very simple things help a lot.
- Keeping the communication asynchronous - while designing integration always assume that the different parts will go down and identify steps needed to control the impact. It’s similar to the earlier example of primary node failing .
- In queuing scenarios, bad messages to be moved to an error queue. Thankfully this feature has been added in SAP PI with 7.3X .
However, there is a class of errors that we’re still susceptible to - anything which has a single point of failure. And these could be things external to your application - your firewall configuration etc.
Digital circuits achieve fault tolerance with some form of redundancy .An example is triple modular redundancy (TMR).

The majority gate is a simple AND–OR circuit - if the inputs to the majority gate are denoted by x, y and z, then the output of the majority gate is . In essence we have three distinct pipelines and the result is achieved by majority voting.
Application integration with ESB is definitely better than using point to point communications but it’s susceptible to single node failures. May be need a more resilient integration system?
b) Regularly induce failures to reduce uncertainty: Thinking of fault tolerance in design certainly helps but there can always be certain category of problems that come with no warning. Further, the damage is more if a service breaks down once in five years than a service which fails every two weeks. Hence, the assertion is that by making it constantly fail, the impact can be minimized. ‘DR tests’ in enterprises are an effort in that direction. However, what happens if we don’t want the failure to be like a fire drill. And in fact most failures in future are going to be the ones we can’t predict. Companies like netflix are already using this strategy. They have their own Simian Army with different kinds of monkeys - Chaos Monkey shuts down virtual instances in production environment - instanced which are serving live traffic to customers. Chaos Gorilla can bring an entire data center and Chaon Kong will bring down an entire region. Then there is latency monkey - it causes addition of latency and this is a much more difficult problem to deal
Mobile Development and Antifragile
My experience with mobile development is only for the last couple of years but there are some distinct patterns I can see here. The languages, frameworks, technologies etc. are fun than some of the broader points that emerge are:
- Being antifragile is a feature: The expectation of users is to have the application performing even under volatile conditions - bad / low internet connectivity. We went in the application with a lot of features and then cut down to make it more performant - this was the most critical feature.
- Parallels between antifragile and agile development. Agile processes have short iterations, test driven design and rapid prototyping - they all indicate that failure is inherent and the best way to get out of it is to acknowledge and learn from it to make corrections. In some ways, agile is more honest than the traditional methods where we think we can calculate all the future estimates, know all the risks and know what’s going to fail. The emphasis is on failure being a source of strength than something to be hidden assuming it’ll never be discovered.
Cloud and Antifragile
I’ve very limited experience with cloud and none of it is in production- AWS for developer machines , using SAP’s HANA trial for the open sap course and another provider for trying out some other technologies. I can see two big benefits :
- It’s easier to try out new iterations making the software development process more agile.
- If a component fails, it’s easier to replace them.
Thinking of Failure
Moving to the original notion of what's the most useful - it is the notion of failure . An antifragile way of developing software does require a shift in way of thinking though.Some of the more important ones being :
- Seeing ‘bugs’ differently : Bugs should be seen as how the system functions under certain situation and the emphasis on what we can learn from it.
- Adoption of a ‘blameless’ culture : Follows from the law of unintended consequences. We create incentives for people to come out as perfect who never fail and consequently we annihilate any change, sometimes slowing down to the extent where we can’t even get much needed changes.
These were some of my thoughts. Like any way of thinking, it may not be an elixir but there are valuable lessons in being antifragile.